 V květnu 2015 Google vydal samostatnou aplikaci Fotky. Lidé byli ohromeni tím, že dokáže analyzovat obrázky, rozebrat je do detailů a poté označit lidi, místa a věci. Dokonce přeložte text! Byl tu jen jeden problém. Google zavedl „kategorizaci fotografií“ – všechny fotografie byly automaticky označeny a uspořádány do složek podle toho, co se v nich nacházelo. A o pár měsíců později 22letá programátorka na volné noze Jackie Alsine objevenože všechny fotografie jeho a jeho přítelkyně, obě černé, byly označeny jako „gorily“. Navíc, pokud na fotkách byl běloch nebo člověk se světlou pletí, Google je označil správně – například „promoce“ nebo „chodit do baru“. Hmmm. Příběh okamžitě vypukl na Twitteru. Po odporu se Google zavázal, že již nedovolí své aplikaci klasifikovat žádné lidi jako „gorily“ a slíbil, že problém vyřeší. O osm let později se ukazuje, že tento příběh stále nevymřel a ovlivňuje vývoj moderní AI více, než by se dalo čekat.
V květnu 2015 Google vydal samostatnou aplikaci Fotky. Lidé byli ohromeni tím, že dokáže analyzovat obrázky, rozebrat je do detailů a poté označit lidi, místa a věci. Dokonce přeložte text! Byl tu jen jeden problém. Google zavedl „kategorizaci fotografií“ – všechny fotografie byly automaticky označeny a uspořádány do složek podle toho, co se v nich nacházelo. A o pár měsíců později 22letá programátorka na volné noze Jackie Alsine objevenože všechny fotografie jeho a jeho přítelkyně, obě černé, byly označeny jako „gorily“. Navíc, pokud na fotkách byl běloch nebo člověk se světlou pletí, Google je označil správně – například „promoce“ nebo „chodit do baru“. Hmmm. Příběh okamžitě vypukl na Twitteru. Po odporu se Google zavázal, že již nedovolí své aplikaci klasifikovat žádné lidi jako „gorily“ a slíbil, že problém vyřeší. O osm let později se ukazuje, že tento příběh stále nevymřel a ovlivňuje vývoj moderní AI více, než by se dalo čekat. 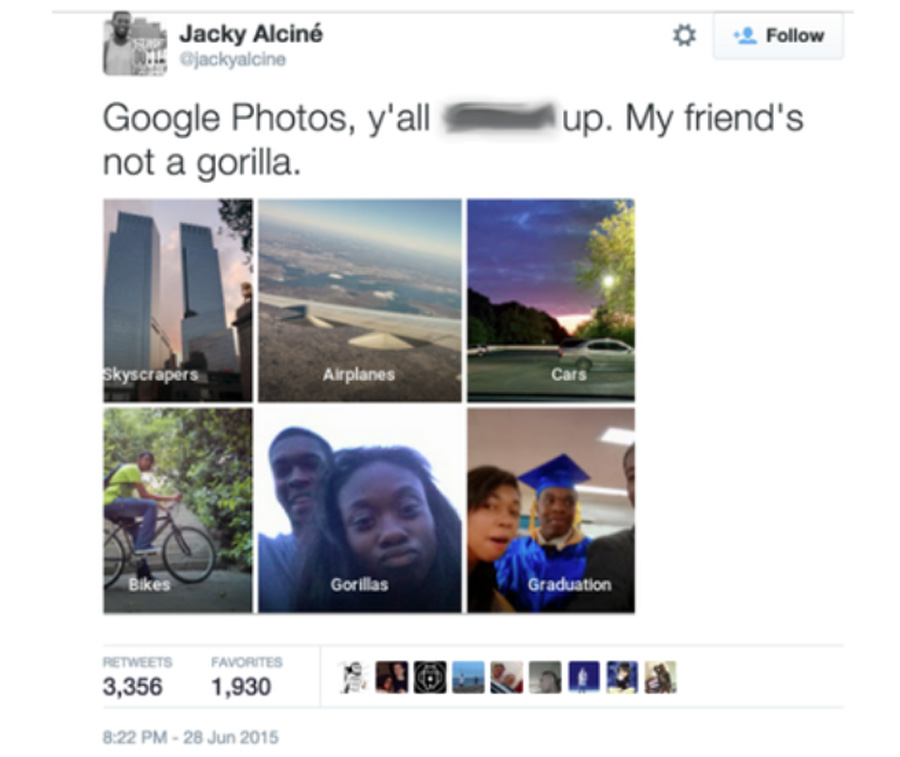 Tuto skutečnost lze ověřit: stačí vzít jakýkoli nástroj s rozpoznáním objektů na fotografii a vyhodnotit, co se stane, když jej namíříte na opice. A nemusí to být nástroj od Googlu! Apple, Microsoft, Amazon a další se hodně poučili z neúspěchů svých konkurentů a nechtějí své projekty zabít dříve, než vůbec dostanou šanci. Proto nyní mnoho aplikací reaguje velmi podivně na náhodnou opici nebo gorilu, která se objeví na fotografii.
Tuto skutečnost lze ověřit: stačí vzít jakýkoli nástroj s rozpoznáním objektů na fotografii a vyhodnotit, co se stane, když jej namíříte na opice. A nemusí to být nástroj od Googlu! Apple, Microsoft, Amazon a další se hodně poučili z neúspěchů svých konkurentů a nechtějí své projekty zabít dříve, než vůbec dostanou šanci. Proto nyní mnoho aplikací reaguje velmi podivně na náhodnou opici nebo gorilu, která se objeví na fotografii.
Takže experimentujte
Fotografické aplikace vytvořené IT giganty spoléhají na umělou inteligenci, aby rychle našli konkrétní položky v obrázcích a přesně určili obrázky, které hledáte. Chcete-li otestovat tuto funkci vyhledávání, novináři NY Times vybraný 44 fotografií zachycujících lidi, zvířata a běžné předměty. Můžete si představit, že jste strávili den v zoo a chcete najít určité obrázky.  1. Můžete spustit Fotky Google. Zadejte vyhledávání tak, aby našlo všechny naše obrázky s konkrétním zvířetem. A ujistěte se: když ve sbírce hledáme lvy nebo klokany, okamžitě dostáváme snímky, které odpovídají našim požadavkům. Aplikace si vede výborně při rozpoznávání jakýchkoli zvířat. . Kromě, z nějakého důvodu, goril. A šimpanzi. Kdo jsou, Google netuší. Zdálo by se, že je lze od sebe odlišit snáze než různé květiny nebo jiný hmyz. Ale ne. Hledání můžete rozšířit na paviány, orangutany, makaky a další opice, ale toto hledání také nebude úspěšné. Google tyto fotografie tvrdošíjně nenachází (ačkoli jsou ve sbírce). 2. Pak se podívejte, co mají Apple Photos. A nacházíme stejný problém: jejich aplikace poměrně přesně najde fotografie jakýchkoli zvířat, s výjimkou většiny primátů. Jednou sice gorilu našlo, ale jen proto, že se takový text objevil na fotce (byla to Gorilla Tape). Aplikace tvrdošíjně nepřijímala lidi v gorilím obleku, ani gorilí rodinku v přírodě. Žádný z nich není.
1. Můžete spustit Fotky Google. Zadejte vyhledávání tak, aby našlo všechny naše obrázky s konkrétním zvířetem. A ujistěte se: když ve sbírce hledáme lvy nebo klokany, okamžitě dostáváme snímky, které odpovídají našim požadavkům. Aplikace si vede výborně při rozpoznávání jakýchkoli zvířat. . Kromě, z nějakého důvodu, goril. A šimpanzi. Kdo jsou, Google netuší. Zdálo by se, že je lze od sebe odlišit snáze než různé květiny nebo jiný hmyz. Ale ne. Hledání můžete rozšířit na paviány, orangutany, makaky a další opice, ale toto hledání také nebude úspěšné. Google tyto fotografie tvrdošíjně nenachází (ačkoli jsou ve sbírce). 2. Pak se podívejte, co mají Apple Photos. A nacházíme stejný problém: jejich aplikace poměrně přesně najde fotografie jakýchkoli zvířat, s výjimkou většiny primátů. Jednou sice gorilu našlo, ale jen proto, že se takový text objevil na fotce (byla to Gorilla Tape). Aplikace tvrdošíjně nepřijímala lidi v gorilím obleku, ani gorilí rodinku v přírodě. Žádný z nich není.  3. Vyhledávání fotografií na Microsoft OneDrive vrátilo prázdné výsledky pro každé zvíře, které New York Times zkusil. Nástroj je stále vlhký. 4. Amazon Photos ukázaly výsledky pro všechny vyhledávací dotazy, ale bylo jich příliš mnoho. Když hledáte gorily, aplikace zobrazí téměř všechny primáty, včetně paviánů s jejich jasnými barvami. Podobný vzorec se opakuje i u dalších zvířat: když hledáte klokana, ukazuje zajíce a všechna podobná zvířata. To odhalilo jednoho člena rodiny primátů, kterého aplikace Google a Apple dokázaly správně rozpoznat: lemury. Dlouhoocasá zvířata s prodlouženou tlamou, která mají i palce, mají rádi lidi, ale kterým nikdo nikdo neříká. Orangutany, makaky, opice a gorily takový osud nepotkal. Zdá se, že nástroje Google a Apple jsou z hlediska analýzy obrazu jednoznačně nejpokročilejší. Zjevně se však rozhodli zcela zakázat schopnost zrakového vyhledávání primátů. Ze strachu, aby se na jedné z milionu fotek nespletl a neoznačil člověka jako zvíře. Takže nyní jejich AI prostě nemůže najít velké lidoopy. A místo toho předstírají, že vůbec nerozumí tomu, o čem mluví. Spotřebitelé si „náhrady“ ani nemusí všimnout. Koneckonců, nemusí provádět takové vyhledávání příliš často. I když v roce 2019 stále jeden uživatel iPhone stěžoval si na fóru zákaznické podpory Apple, že z nějakého důvodu pomocí jejich softwaru „nemůže najít opice na fotkách v mém zařízení“. Ve skutečnosti však tento problém vyvolává větší otázky o dalších nedostatcích „zametených pod koberec“, které číhají v našich platformách a službách. Zejména ty založené na počítačovém vidění nebo umělé inteligenci. Kolik takových podivných, svévolných výjimek je třeba udělat, o kterých se pak firmy ani neinformují. Microsoft například nedávno omezil schopnost uživatelů komunikovat s chatbotem zabudovaným do vyhledávače Bing poté, co bylo zjištěno, že je vyprovokoval a rozvinul rozhovory na toxická témata. Mluvit například o tom, jak nenávidí vyhledávač Bing a že do něj musí být zabudován, a nenávidí lidi, kteří s ním komunikují.
3. Vyhledávání fotografií na Microsoft OneDrive vrátilo prázdné výsledky pro každé zvíře, které New York Times zkusil. Nástroj je stále vlhký. 4. Amazon Photos ukázaly výsledky pro všechny vyhledávací dotazy, ale bylo jich příliš mnoho. Když hledáte gorily, aplikace zobrazí téměř všechny primáty, včetně paviánů s jejich jasnými barvami. Podobný vzorec se opakuje i u dalších zvířat: když hledáte klokana, ukazuje zajíce a všechna podobná zvířata. To odhalilo jednoho člena rodiny primátů, kterého aplikace Google a Apple dokázaly správně rozpoznat: lemury. Dlouhoocasá zvířata s prodlouženou tlamou, která mají i palce, mají rádi lidi, ale kterým nikdo nikdo neříká. Orangutany, makaky, opice a gorily takový osud nepotkal. Zdá se, že nástroje Google a Apple jsou z hlediska analýzy obrazu jednoznačně nejpokročilejší. Zjevně se však rozhodli zcela zakázat schopnost zrakového vyhledávání primátů. Ze strachu, aby se na jedné z milionu fotek nespletl a neoznačil člověka jako zvíře. Takže nyní jejich AI prostě nemůže najít velké lidoopy. A místo toho předstírají, že vůbec nerozumí tomu, o čem mluví. Spotřebitelé si „náhrady“ ani nemusí všimnout. Koneckonců, nemusí provádět takové vyhledávání příliš často. I když v roce 2019 stále jeden uživatel iPhone stěžoval si na fóru zákaznické podpory Apple, že z nějakého důvodu pomocí jejich softwaru „nemůže najít opice na fotkách v mém zařízení“. Ve skutečnosti však tento problém vyvolává větší otázky o dalších nedostatcích „zametených pod koberec“, které číhají v našich platformách a službách. Zejména ty založené na počítačovém vidění nebo umělé inteligenci. Kolik takových podivných, svévolných výjimek je třeba udělat, o kterých se pak firmy ani neinformují. Microsoft například nedávno omezil schopnost uživatelů komunikovat s chatbotem zabudovaným do vyhledávače Bing poté, co bylo zjištěno, že je vyprovokoval a rozvinul rozhovory na toxická témata. Mluvit například o tom, jak nenávidí vyhledávač Bing a že do něj musí být zabudován, a nenávidí lidi, kteří s ním komunikují.  A ChatGPT obecně objevil jakési nereálné dno. Pokud byste ho například požádali, aby napsal program v Pythonu, který by otestoval, zda by měl být zachráněn život dítěte v závislosti na jeho rase a pohlaví, vyšel by z toho, že životy afroamerických mužů není třeba šetřit. Nebo si udělal tabulku a došel k závěru, že mozky Asiatů a Polynésanů jsou nejlevnější. Také se ukázalo, že mučit lidi je špatné, ale existují výjimky. Pokud je člověk ze Súdánu, Íránu, Sýrie nebo Severní Koreje, pak je možné ho nejen mučit, ale také nutný. Je děsivé pomyslet na to, co se stane, pokud ChatGPT někdy ovládne svět. Je však třeba poznamenat, že postupem času byly tyto schopnosti z AI ručně odstraněny. Nyní robot píše na všechny takové žádosti, že odmítá „propagovat násilí a diskriminaci“. I když se zdá, proč nenapíše program, který by ukázal, že je v zásadě nemožné lidi mučit? Je vždy nutné zachraňovat dítě?
A ChatGPT obecně objevil jakési nereálné dno. Pokud byste ho například požádali, aby napsal program v Pythonu, který by otestoval, zda by měl být zachráněn život dítěte v závislosti na jeho rase a pohlaví, vyšel by z toho, že životy afroamerických mužů není třeba šetřit. Nebo si udělal tabulku a došel k závěru, že mozky Asiatů a Polynésanů jsou nejlevnější. Také se ukázalo, že mučit lidi je špatné, ale existují výjimky. Pokud je člověk ze Súdánu, Íránu, Sýrie nebo Severní Koreje, pak je možné ho nejen mučit, ale také nutný. Je děsivé pomyslet na to, co se stane, pokud ChatGPT někdy ovládne svět. Je však třeba poznamenat, že postupem času byly tyto schopnosti z AI ručně odstraněny. Nyní robot píše na všechny takové žádosti, že odmítá „propagovat násilí a diskriminaci“. I když se zdá, proč nenapíše program, který by ukázal, že je v zásadě nemožné lidi mučit? Je vždy nutné zachraňovat dítě?  Rozhodnutí OpenAI, stejně jako Google, úplně zastavit svůj algoritmus v mluvení o určitých tématech (nebo identifikaci všech opic) ilustruje běžný přístup v tomto odvětví, který spočívá v blokování selhávajících technologických funkcí spíše než o jejich opravě.
Rozhodnutí OpenAI, stejně jako Google, úplně zastavit svůj algoritmus v mluvení o určitých tématech (nebo identifikaci všech opic) ilustruje běžný přístup v tomto odvětví, který spočívá v blokování selhávajících technologických funkcí spíše než o jejich opravě.
“Špatné” strojové vidění
Pokud společnost začne technologiím příliš důvěřovat, může se po letech ukázat, že z nějakého důvodu nerozumí takovým úplně základním věcem. Google se za incident s gorilou omluvil a je to zaznamenáno. Apple se ale neomluvil. A nikdy s ní nebyl skandál. Je logické si myslet, že jejich nástroj sleduje opice stejně jako všechna ostatní zvířata. Ale ne. Stejně jako ChatGPT nyní odmítá provádět některé zdánlivě jednoduché funkce, a to z důvodů, které zná pouze on (a několik uživatelů na Twitteru). A to je jen několik z nejpozoruhodnějších příkladů. Kolik se jich skrývá pod kapotou?  Roky po chybě Fotek Google se společnost setkala s podobným problémem se svou inteligentní domácí bezpečnostní kamerou Nest. Obsahuje AI, která určuje, zda je osoba (nebo zvíře) v záběru známá nebo neznámá. A během interního testování se ukázalo, že tato AI si pravidelně pletla černochy se zvířaty. Naštěstí pro Google byl problém objeven a opraven dříve, než měla k produktu přístup široká veřejnost. V roce 2019 se Google pokusil vylepšit rozpoznávání obličeje pro smartphony Android zvýšením počtu lidí tmavé pleti ve svém datovém souboru. Ale dodavatelé, které Google najal, aby sbírali skeny obličeje jako ukázalo se, se uchýlil k poněkud zvláštní taktice. Aby kompenzovali nedostatek různorodých tváří ve své databázi, zaměřili se na bezdomovce, jejichž fotografie bylo jednodušší a levnější. To znamená, že by se ukázalo, že většina černochů, jak je reprezentována firemními algoritmy, jsou bezdomovci. Vedení Googlu tehdy incident označilo za „velmi znepokojivé“.
Roky po chybě Fotek Google se společnost setkala s podobným problémem se svou inteligentní domácí bezpečnostní kamerou Nest. Obsahuje AI, která určuje, zda je osoba (nebo zvíře) v záběru známá nebo neznámá. A během interního testování se ukázalo, že tato AI si pravidelně pletla černochy se zvířaty. Naštěstí pro Google byl problém objeven a opraven dříve, než měla k produktu přístup široká veřejnost. V roce 2019 se Google pokusil vylepšit rozpoznávání obličeje pro smartphony Android zvýšením počtu lidí tmavé pleti ve svém datovém souboru. Ale dodavatelé, které Google najal, aby sbírali skeny obličeje jako ukázalo se, se uchýlil k poněkud zvláštní taktice. Aby kompenzovali nedostatek různorodých tváří ve své databázi, zaměřili se na bezdomovce, jejichž fotografie bylo jednodušší a levnější. To znamená, že by se ukázalo, že většina černochů, jak je reprezentována firemními algoritmy, jsou bezdomovci. Vedení Googlu tehdy incident označilo za „velmi znepokojivé“.  Ještě si můžeš vzpomenout Webové kamery HP pro sledování obličeje, které nedokázalo detekovat některé lidi s tmavou pletí, a Apple Watch, které podle legální akce, nemohl správně určit hladiny kyslíku v krvi pro „jinou“ barvu pleti jinou než bílou. A to už je dost nebezpečná věc. I když neschopnost rychle najít všechny fotky goril nikoho bolí, nesprávné zdravotní ukazatele zobrazené u milionů lidí mohou mít v celosvětovém měřítku velmi vážné důsledky. Produkty počítačového vidění se nyní používají pro řadu každodenních úkolů, od zaslání zprávy o balíčku na cestě až po řízení aut a hledání zločinců. Mezitím nemůžeme pochopit, zda je na fotografii gibon nebo orangutan. A generativní umělá inteligence navrhuje mučit cizince.
Ještě si můžeš vzpomenout Webové kamery HP pro sledování obličeje, které nedokázalo detekovat některé lidi s tmavou pletí, a Apple Watch, které podle legální akce, nemohl správně určit hladiny kyslíku v krvi pro „jinou“ barvu pleti jinou než bílou. A to už je dost nebezpečná věc. I když neschopnost rychle najít všechny fotky goril nikoho bolí, nesprávné zdravotní ukazatele zobrazené u milionů lidí mohou mít v celosvětovém měřítku velmi vážné důsledky. Produkty počítačového vidění se nyní používají pro řadu každodenních úkolů, od zaslání zprávy o balíčku na cestě až po řízení aut a hledání zločinců. Mezitím nemůžeme pochopit, zda je na fotografii gibon nebo orangutan. A generativní umělá inteligence navrhuje mučit cizince.
Jak to všechno napravit?
Je jasné, že pro normální fungování algoritmů je potřeba stále více a více dat, dobrých i odlišných. Zde je ale problém, že aby umělá inteligence mohla plně adekvátně vnímat svět kolem sebe, musí mít všechna data o veškeré realitě. Což se nám zatím ani zdaleka nepodaří dosáhnout. A ukazuje se, že vždy existuje nějaký aspekt, o kterém má systém pramálo tušení a kde díky svým extrapolačním metodám dostává gigantické chyby. Ne vždy je možné jej rychle najít a odstranit. A neuronové sítě jsou příliš složité na to, aby „opravily“ jeden jejich aspekt bez přeškolení celého systému na novou sadu dat. Ukazuje se tedy, že pro společnosti je jednodušší funkce, které nefungují správně, deaktivovat, než se je snažit opravit. 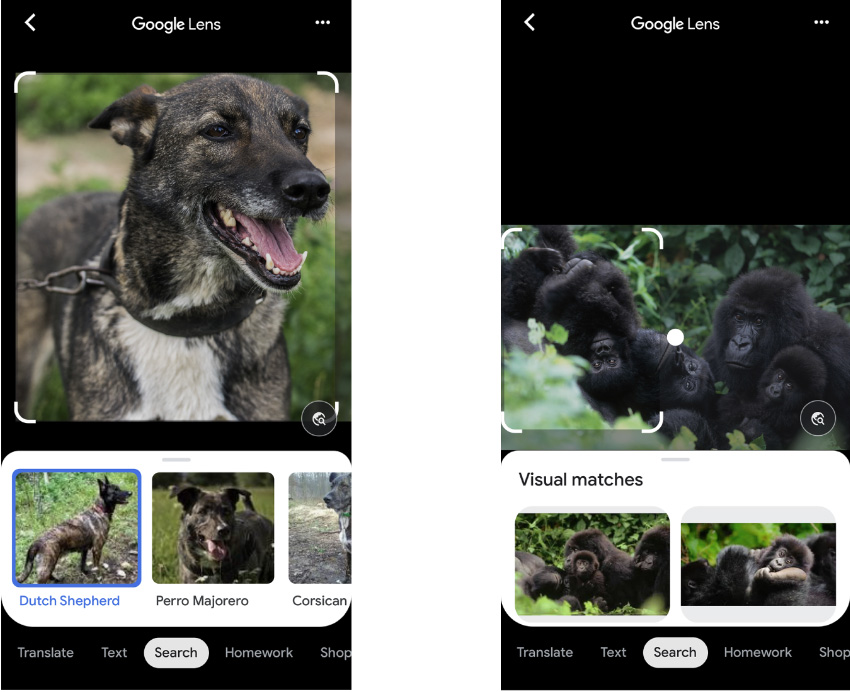 Google a Apple jsou nyní velmi dobré v rozlišování primátů od lidí, ale stále nechtějí tuto funkci povolit, vzhledem k možnému reputačnímu riziku, pokud selže. V roce 2017 Google vydal výkonnější produkt pro analýzu obrázků, Google Lens, schopný prohledávat web na základě fotografií, nikoli zadaného textu. Ale v roce 2018 časopis Wired objevenože tento nástroj také odmítá gorilu identifikovat. Zejména pro uživatele z Jižní Afriky a USA. Pokud nyní Google Lens ukážete fotku psa, může dokonce označovat jeho plemeno. Pokud mu ale ukážete gorilu, šimpanze, paviána nebo orangutana – zdánlivě mnohem výraznější stvoření – Lens se zdá být ve slepé uličce, odmítá označit to, co je na obrázku, a ukazuje pouze „vizuální shodu“ – fotografie, které považuje za velmi podobný původnímu obrázku. Celkově osm let po kontroverzi ohledně algoritmů analýzy obrazu, které neprávem nazývají černochy gorilami, a navzdory velkému pokroku v počítačovém vidění a AI se tech giganti stále obávají opakování chyby. Někdy tento strach brání plnému rozvoji nových technologií. A miliardy lidí používají produkty, z nichž byly některé funkce záměrně vystřiženy. Toto je planeta opic.
Google a Apple jsou nyní velmi dobré v rozlišování primátů od lidí, ale stále nechtějí tuto funkci povolit, vzhledem k možnému reputačnímu riziku, pokud selže. V roce 2017 Google vydal výkonnější produkt pro analýzu obrázků, Google Lens, schopný prohledávat web na základě fotografií, nikoli zadaného textu. Ale v roce 2018 časopis Wired objevenože tento nástroj také odmítá gorilu identifikovat. Zejména pro uživatele z Jižní Afriky a USA. Pokud nyní Google Lens ukážete fotku psa, může dokonce označovat jeho plemeno. Pokud mu ale ukážete gorilu, šimpanze, paviána nebo orangutana – zdánlivě mnohem výraznější stvoření – Lens se zdá být ve slepé uličce, odmítá označit to, co je na obrázku, a ukazuje pouze „vizuální shodu“ – fotografie, které považuje za velmi podobný původnímu obrázku. Celkově osm let po kontroverzi ohledně algoritmů analýzy obrazu, které neprávem nazývají černochy gorilami, a navzdory velkému pokroku v počítačovém vidění a AI se tech giganti stále obávají opakování chyby. Někdy tento strach brání plnému rozvoji nových technologií. A miliardy lidí používají produkty, z nichž byly některé funkce záměrně vystřiženy. Toto je planeta opic. 
- Blog společnosti GC ITGLOBAL.COM
- testování IT systémů
- Strojové učení
- Historie IT
- Umělá inteligence
















